
One of the least appreciated transparency measures in the EU’s new Digital Services Act (DSA) is the requirement for platforms to send the Commission information about each individual content moderation action, and for the Commission to make that information available in a public database. (Art. 24.5, R. 66) A database like that sounds like a dream-come-true for many researchers — especially since the DSA says platforms have to pay for it. But the devil is always in the details. The DSA’s database requirement has a lot of those.
On June 21, the Commission released draft technical specifications for the API that platforms will use to submit information to the database. It sought public comments, which are due by July 17. These API specifications are important. They will shape both platforms’ internal operations and the public’s access to a potential treasure trove of new information. In a normal year for platform regulation, they would be the object of intense discussion among researchers, academics, and civil society. This year, so much is going on that the whole topic has been very much under the radar. I myself didn’t register that the consultation was happening until four days before the comment deadline. (So, caveat emptor, this summary is hasty and there is ample room for mistakes. I’ll post corrections in here if people spot important ones.)
This lack of attention and more careful discussion is quite unfortunate. It is hard to understand what information the API specifications are asking for, and in many cases I think they are asking for the wrong thing. Non-coders can best understand them by reading the API documentation; others can glean more from the Github code repository. The latter is not very legible to me, but it does charmingly includes notes like “hold on to your butts.”
Larry Lessig’s famous Internet law dictum tells us that “code is law” — meaning that the technical choices made by private companies, including platforms, effectively regulate and shape users’ choices for online behavior. That’s precisely what laws like the DSA are trying to constrain, and subject to more public oversight. The Commission’s API specifications are a different form of code-as-law. They literally use legal authority to dictate the code adopted by private companies in their content moderation operations. That means that, this time around, the regulators are the ones whose code risks moving fast and breaking things.
The API specifications will of course shape companies’ submissions to the database. But the technical specifications will also reshape what platforms actually do in their content moderation. The biggest platforms (Very Large Online Platforms or VLOPs) have been gearing up for an August DSA compliance deadline for many months. For them, the specifications introduce some brand new obligations, and will require last-minute retooling to track categories of information that the DSA itself never mentioned. The situation is worse, as always, for the vast number of smaller platforms. Everyone above the “small and micro” platform size has to send information to the database, but most of them don’t have to start complying until January. When they do, though, they will presumably be stuck adapting to standards negotiated by their giant, incumbent competitors.
The DSA’s database of platform content moderation actions is a remarkable undertaking, and could create a truly novel and valuable resource. But it’s also very complicated. Judgment calls made now will shape the future of both the database itself and internal platform operations. We would all be better off if the Commission had left itself more time to consult with experts, carefully craft the API specifications, and sweat the details of this very consequential new code.
What is this Database?
The DSA requires platforms to notify users about any moderation actions taken against their content or accounts. Removals, algorithmic demotions, demonetization actions, account suspensions, “shadow banning,” etc. all trigger this notice under Article 17, known in DSA parlance as a “Statement of Reasons” or SOR.
The big exceptions to the SOR requirement are
(1) No Article 17 SORs are required for “deceptive high-volume commercial content,” which approximately-but-not-quite means spam. So those won’t be in the database. (Art. 17, R. 55)
(2) No Article 17 SORs are required if content is removed pursuant to a government order, although those users do get a different form of notification. (Art. 55.5; Art. 9.5) So information about government orders apparently won’t be in the database either.
(3) It appears that platforms do still have to send SORs even if they know it might tip off a criminal to an ongoing law enforcement investigation. They also seemingly must do so even if they have such a strong suspicion of a “criminal offence involving a threat to … life or safety” that they must, under another part of the DSA, notify law enforcement. (Art. 18) Platforms may decide they have ethical obligations to nonetheless withhold SORs in those situations — presumably meaning they would also be missing from the database.
The database is intended to be a “publicly accessible machine-readable” compendium of the Article 17 SORs, each of which must be sent to the Commission. (Art. 24.5) In theory that means it will contain SORs for everything but the spam and government-order based removals listed above. But there are also other important limitations.
(1) As far as I can tell, the DSA does not require platforms to add information about appeals (Art 20) or out-of-court dispute resolutions (Art 21) and their outcomes to the database. That leaves it as something like a record of first instance court decisions, but not appellate decisions.
(2) Platforms must “ensure that the information submitted does not contain personal data.” That raises a couple of real restrictions.
(a) First, the SORs submitted to the database must not have any information that would identify individual users or notifiers, such as names or social media handles. That includes the URLs of the affected content, if the URLs can be used to identify the account holder or other personal information. (If Twitter removed my post about the API specification, for example, its SOR would include the URL https://twitter.com/daphnehk/status/1679388559143235584.)
(b) URLs can also convey personal data if they link to content that itself contains information about people. For example, a URL would have this problem if it linked to a blog post about celebrity gossip, or a Facebook post wishing a friend a happy birthday. The same problem could arise for URLs that contain an image or video of a person. This concern about data protection issues with the content referenced by a URL has been a key element of Right to Be Forgotten analysis for data protection authorities. But the Right to Be Forgotten at least has limitations that permit continued disclosure of URLs linking to important information about public figures. The DSA’s flat ban on “personal data” would seem to mean the database must exclude even URLs that link to widely reported news (or disinformation).
This problem would, theoretically, go away if the URL submitted to the database linked only to content that had already been removed by its host. In that case, database users would know the URL but not what content used to be there. Platforms still can’t safely submit those URLs to the database, though. Under the DSA, that same content could easily be reinstated later, at the same URL, after an appeal by the affected user.
(c) Database submissions of individual SORs may contain no personal information themselves, yet become a source of personal information when aggregated with other data or with other SORs in the database. This involves the same set of complex problems I described here. Those problems would likely need to be mitigated at the level of the database itself, since individual platforms will not always be able to control for the risks that arise from data in aggregate.
I worry that all these limitations will leave the database far less useful than its creators envisioned. The exclusion of spam, removal orders, and appeals and other later developments will leave the database with unfortunate gaps. The exclusion of personal information will prevent researchers from seeing the actual content affected by many removals, and will likely mean that many millions of SORs included in the database will be all but indistinguishable. An example of this that I used on Twitter was “the twenty-thousandth self-initiated, automated FB removal this week of content violating its nudity policy.” Another user responded, all too accurately, “and that would be Monday by breakfast.”
What’s in the API proposal?
The API proposal reads very much like a first draft. If this were part of a responsible platform API launch, it would get several rounds of feedback and iteration before being finalized. The Commission’s process of iterative improvement is likely to be very limited, though, given that the biggest platforms are supposed to begin implementing these requirements in August.
Practical Issues
The specification has lots of little issues that are more practical than legal or policy related. It has a fixed list of countries that can be referenced when platforms report territorial restrictions on content access, for example. Future-proofing to allow inclusion of new EU countries or optional info about geoblocking affecting non-EU countries would be better. And the list of “content types” includes video, text, images, and “other” – leaving no way to report clearly on common formats like audio files, or memes that combine images and text. There are also provisions that I personally, as someone who has worked in this field for a long time, just can’t parse. (I can’t tell the difference between “DECISION_PROVISION_TOTAL_TERMINATION” and “DECISION_ACCOUNT_TERMINATED,” for example.)
Bigger Problems
Other choices in the API specification are more consequential. There doesn’t seem to be a way to update the database with the result of an appeal (which would be nice to enable as an option, whether or not the DSA requires it), for example — or even to cross-reference later developments to an earlier UUID for purposes like error-correction. And platforms are required to include URLs, despite the privacy concerns described above. (If I were a platform lawyer trying to comply with the API specification without violating the GDPR or the letter of the DSA, I might put in obviously fake URLs like platform.com/redacted_account/redacted_post.html)
Content Classification
Probably the weirdest thing in the API specification is its list of required “category” tags, explaining the reason that each item of content was moderated. It offers eight substantive options (piracy, discrimination, counterfeiting, fraud, terrorism, child safety, non-consensual nudity, misinformation) and two catch-alls (Terms of Service violations and “uncategorized”). I’m pasting the entire list and explanatory text below, because the substantive options get even weirder once you look more closely. The terrorism category seems to conflate hate speech and terrorism, for example. Meanwhile, the discrimination category conflates highly criminal hate speech with much milder and potentially even lawful forms of discrimination. None of the categories seem to cover ordinary pornography, which makes up a huge portion of content moderation.
I am pretty sure (but not 100%) that the list is intended to encompass both truly illegal content and content that is lawful but violates platforms’ own rules. So a platform might use the child safety category for both (1) highly illegal sexual abuse material and also (2) lawful material that the platforms’ Terms of Service prohibit, like images of nude children in medical literature or Renaissance paintings. (The specification says that this category includes “child nudity.”) A researcher using the database would be able to distinguish whether the platform relied on law or its Terms of Service for a particular decision by checking the “decision grounds” field.
Expansive New Legal Review of All Moderated Content?
The biggest policy problem I see with the API specifications is that it appears to require a major undertaking far beyond what the DSA itself mandates. The “INCOMPATIBLE_CONTENT_ILLEGAL” field is “a required attribute and it must be in the form ‘Yes’ or ‘No’” in order to “indicate[] to us that not only was the content incompatible [with Terms of Service] but also illegal.” Complying with that would require major changes for platforms. Most platforms use their Terms of Service to prohibit far more content than the law does, and have moderators trained to understand and enforce only the simpler, globally enforced standards of the Terms of Service.
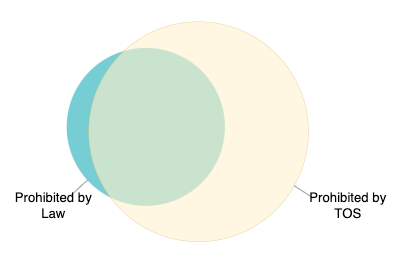
Legal specialists only get involved if content is permitted by Terms of Service, but there is reason for concern that it is nonetheless prohibited under national law. (That’s the blue sliver in the diagram.) The API specification seems to mean that lawyers must also get involved in reviewing billions of items that were already subject to removal for violating the Terms of Service. (That’s everything in the yellow circle of the diagram). The outcome of this additional review would be interesting to know, but very costly — and it would make no difference to the affected user or the platform, since the content would already be removed under the TOS. And of course, in real life, content is often not crisply legal or illegal. At most, the data submitted using this field would show one person’s guess, made very rapidly, about often-complex legal questions.
The idea of requiring platforms to make this unnecessary-but-interesting legal assessment for every single item of content they moderate was discussed in the DSA legislative process, as well as in disputes under Germany’s NetzDG. Lawmakers ultimately did not include such a mandate in the DSA. Adding it as part of a technical specification would be an extreme circumvention of the democratic process. Hopefully that is not what drafters intended. If so, it’s awfully hard to tell from their documentation.
Conclusion
Platforms have made an awful lot of mistakes over the years by rushing to ship products without waiting to identify or fix their problems. The EU Commission has been falling into a similar pattern lately. Its 2019 copyright filtering mandate, for example, was passed before lengthy consultations that illustrated the near-impossibility of actually complying with the law. The Commission wound up issuing detailed and complex guidance telling Member States how to implement that law, but published the guidelines just days before those countries’ 2021 deadline for doing so. Most countries simply, and understandably, missed their compliance deadlines — with little or no consequence. Platforms regulated by the DSA, and struggling to interpret late-arriving information like the database API specifications, may not have such leeway. The database API specifications are just one aspect of the DSA being rushed to launch this summer. We should hope that EU regulators, with their new authority to shape platforms’ technologies and behavior, don’t replicate platforms’ own mistakes.
APPENDIX
From API documentation:
Content Type (content_type)
This is a required attribute, and it tells us what type of content is targeted by the statement of reason.
The value provided must be one of the following:
· STATEMENT_CATEGORY_PIRACY
o Pirated content (eg. music, films, books)
· STATEMENT_CATEGORY_DISCRIMINATION
o Discrimination and hate speech (e.g. race, gender identity, sexual orientation, religion, disability)
· STATEMENT_CATEGORY_COUNTERFEIT
o Counterfeit goods (e.g. fake perfume, fake designer brands)
· STATEMENT_CATEGORY_FRAUD
o Scams, frauds, subscription traps or other illegal commercial practices
· STATEMENT_CATEGORY_TERRORISM
o Terrorist content (e.g. extremists, hate groups)
· STATEMENT_CATEGORY_CHILD_SAFETY
o Child safety (e.g. child nudity, sexual abuse, unsolicited contact with minors)
· STATEMENT_CATEGORY_NON_CONSENT
o Non-consensual nudity (e.g. hidden camera, deepfake, revenge porn, upskirts)
· STATEMENT_CATEGORY_MISINFORMATION
o Harmful False or Deceptive Information (e.g. denying tragic events, synthetic media, false context)
· STATEMENT_CATEGORY_VIOLATION_TOS
o Violation of the terms of service of the Internet hosting service (e.g. spam, platform manipulation)
· STATEMENT_CATEGORY_UNCATEGORISED
o Uncategorised